
Your AI Should Know When It Got It Wrong
Most AI tools have a dirty little secret: they don’t know when they fail.
You ask, they answer. Maybe it was great. Maybe it was garbage. The tool has no idea, and more importantly - it doesn’t care. Next time you ask, it will do exactly the same thing it did before, with exactly the same probability of getting it wrong. That’s not intelligence. That’s a very expensive autocomplete.
I built KAIPARR to work differently. But before I explain how, it’s worth being honest about the two problems that make this genuinely hard - because most AI systems pretend neither of them exists.
Problem One: The Stakes Are Asymmetric
Here’s the thing about personal AI automation: when it works, it saves you time and mental energy. When it fails - quietly, without telling you - it doesn’t just waste your time. It erodes trust. You start checking the AI’s work. You start working around it. Eventually you stop using it.
Most AI systems solve this with a thumbs-up / thumbs-down button and call it a day. That’s better than nothing. But it’s also lazy. It assumes you’ll catch every bad output, remember to rate it, and that your explicit feedback is the only signal worth collecting.
That assumption is wrong.
Problem Two: The Non-Determinism Problem - And Why It Doesn’t Go Away
Here’s something the AI industry doesn’t talk about enough: language models are not deterministic. Run the same prompt twice and you will get two different outputs. Maybe slightly different. Maybe meaningfully different. That’s not a bug - it’s a fundamental property of how these systems work. The model is sampling from a probability distribution every time it generates a token. Randomness is baked in by design.
This creates a genuinely hard problem for any system that tries to measure AI quality over time.
If the AI produces a different output every run, what does it mean when quality scores improve? Was it the better prompt? A different day? A model update from the provider? You can’t rerun the test with a clean control. You can’t hold everything constant. The thing you’re measuring keeps moving.
And here’s the uncomfortable corollary: using AI to evaluate AI doesn’t escape this problem. A quality reviewer is also a language model. It’s adversarially configured and calibrated, but it’s still probabilistic. Two reviews of the same output on the same day might not produce identical scores.
The answer isn’t to pretend the problem is solved. It’s to build a stack of signals with fundamentally different reliability properties - and to be honest about which is which. Not all signals are created equal. Some are probabilistic. Some are binary. And the most reliable signal in the whole system has nothing to do with AI at all.
The Brute-Force Temptation - And Why It Fails
There is an approach some frameworks have landed on that tries to address both problems at once: run the model multiple times, score each output, keep the best one. Loop until good. Frameworks like OpenClaw and Hermes have built their quality story around exactly this pattern.
It sounds compelling. It is also expensive - you’re running the model three, five, ten times to produce one answer. And it still doesn’t escape either problem. Stakes-wise, you’re still not learning anything; you’re just paying more per answer and hoping the law of averages works in your favor. Non-determinism-wise, the scoring function that decides which output is “good enough” is itself a language model. It’s probabilistic. “Loop until good” is really “loop until a probabilistic evaluator decides it’s probably good enough.” That’s a different thing, and it’s worth being clear-eyed about the distinction.
The alternative is to stop trying to brute-force quality at runtime and start building a system that actually gets better over time. That’s what the rest of this post is about.
How KAIPARR Is Built Around A Quality Signal Hierarchy
The signal stack has three tiers, and the design logic flows from the reliability properties of each.
At the base: deterministic checks. Structural failures - a tool that wasn’t called, a template variable left unreplaced, a broken reference in a prompt - are binary. They either happened or they didn’t. No model, no judgment, no randomness. These are ground truth and they’re treated that way.
In the middle: probabilistic AI evaluation. Any AI-based quality review introduces statistical noise by definition. KAIPARR manages this by aggregating across many runs rather than trusting any single score, and by looking for persistent patterns - consistent failures, sustained high performance - rather than point-in-time readings. One bad score is data. A streak of bad scores is a signal.
At the top: you. This is the part that gets underappreciated in most AI system designs. When you correct the AI - when you say “that’s wrong” or re-ask the same question because the first answer didn’t cut it - that’s not probabilistic. That happened. It’s a fact. Your behavior as a user is the most reliable quality signal in the entire system, because it’s grounded in the one thing no model can fake: whether the output actually worked for you in the real world.
This hierarchy shapes everything about how KAIPARR weights signals when deciding whether to generate a learning proposal. Deterministic failures are immediate and decisive. AI quality scores accumulate and aggregate. User signals - corrections, flags, explicit thumbs - carry the most weight of all.
None of this is finished work. The non-deterministic nature of LLMs means there’s no stable floor we can stop at. Model providers update their models. Behavior shifts over time. An automation that worked reliably in January may start drifting in April for reasons entirely outside KAIPARR’s control. The quality loop has to keep running, indefinitely, because the environment it’s measuring keeps changing underneath it.
That’s the design philosophy: not a quality gate you pass through once, but a continuous monitoring system that treats improvement as a direction rather than a destination.
Here’s how each tier works in practice.
Tier One: Deterministic Signals
Every time KAIPARR runs an automation - what the broader AI community calls an agent - a scheduled digest, a skill, a conversation - it logs a detailed quality record. Not just “did it succeed or fail.” It captures which tools were called, whether those calls returned useful results, how long the output was (very short outputs are a red flag), whether any connected services threw errors, and a fingerprint of the exact prompt version that was running at the time.
That last part matters more than it might seem. When you flag a problem a week from now, the system needs to know: was this a problem with the instructions that were running then, or the instructions running today? Those are different questions with different answers. Version-aware logging is how you avoid conflating them.
Beyond logging, there are two other classes of deterministic signal. First: AI outputs contain signals about their own quality - hedging language, apologies, qualifications, statements that nothing was found. Most systems ignore those signals. KAIPARR scans every output for them and automatically flags runs where the AI is clearly telling you, in its own words, that something went wrong.
Second: structural failures. Things like a tool that was supposed to be called but wasn’t, or a template variable that survived into the final output unreplaced. These are binary - they either happened or they didn’t. No model, no judgment, no randomness. When they’re found, the run is scored as a failure immediately. Cheaper. Faster. Correct.
Tier Two: Probabilistic AI Evaluation
This is the part I find genuinely interesting as an architecture decision: KAIPARR has an internal critic.
After a job runs, a separate AI evaluation - deliberately set up to be skeptical - reads the original task, what tools were called, and the final output. It scores the quality on a numeric scale, with a clear pass/fail threshold. It also lists the specific problems it found and makes one concrete suggestion for improvement.
I call this the Adversarial Quality Review, or AQR.
The AQR doesn’t run on every job - that would be expensive and redundant. It samples at different rates depending on job type, and always escalates to a full review when the output showed low confidence, when tool errors occurred, or when enough consecutive runs have failed without review coverage. No blind spots.
And because the AQR is itself a language model - probabilistic by definition - no single score is treated as decisive. What matters is the pattern across many runs. One bad score is data. A streak of bad scores is a signal.
Tier Three: User Feedback - Explicit and Implicit
Yes, there’s a thumbs-up / thumbs-down. But KAIPARR is also watching your behavior in ways you don’t have to think about.
If your reply opens with a correction - “no,” “actually,” “that’s wrong” - the previous output gets tagged accordingly. The AI was wrong and you had to fix it. If you ask essentially the same question twice in a row, the system infers the first answer didn’t satisfy you. A clean, single-turn exchange that ended naturally registers as a positive signal.
None of this requires you to do anything extra. You just interact normally. The system collects the signal.
There’s also a flag button for when something is systematically wrong - not just “this output was bad” but “something about how this is built needs to change.” When you flag, the system captures your note in your own words, records the exact prompt version active at that moment, and triggers the learning job immediately. It doesn’t wait for the overnight run.
The Learning Job
Every night - and immediately whenever a flag is submitted - KAIPARR runs what I call the Skill Learning Job. This is the engine.
It works through recent data for every active automation, looking for patterns that signal something needs attention: error rates too high, tool calls consistently returning nothing, outputs that are suspiciously short, errors from connected services. When those patterns appear, the automation gets escalated to deeper analysis.
For automations with a track record of failing quality reviews, the system moves into active improvement mode. It gathers the specific issues the critic identified, the suggestions it made, and the recent tool call patterns - then asks Claude to generate a refined version of the prompt that directly addresses those documented problems.
It also tracks declining quality over time, not just outright failures. A gradual downward drift in quality scores - even without anything breaking - is a different problem, and it gets treated accordingly.
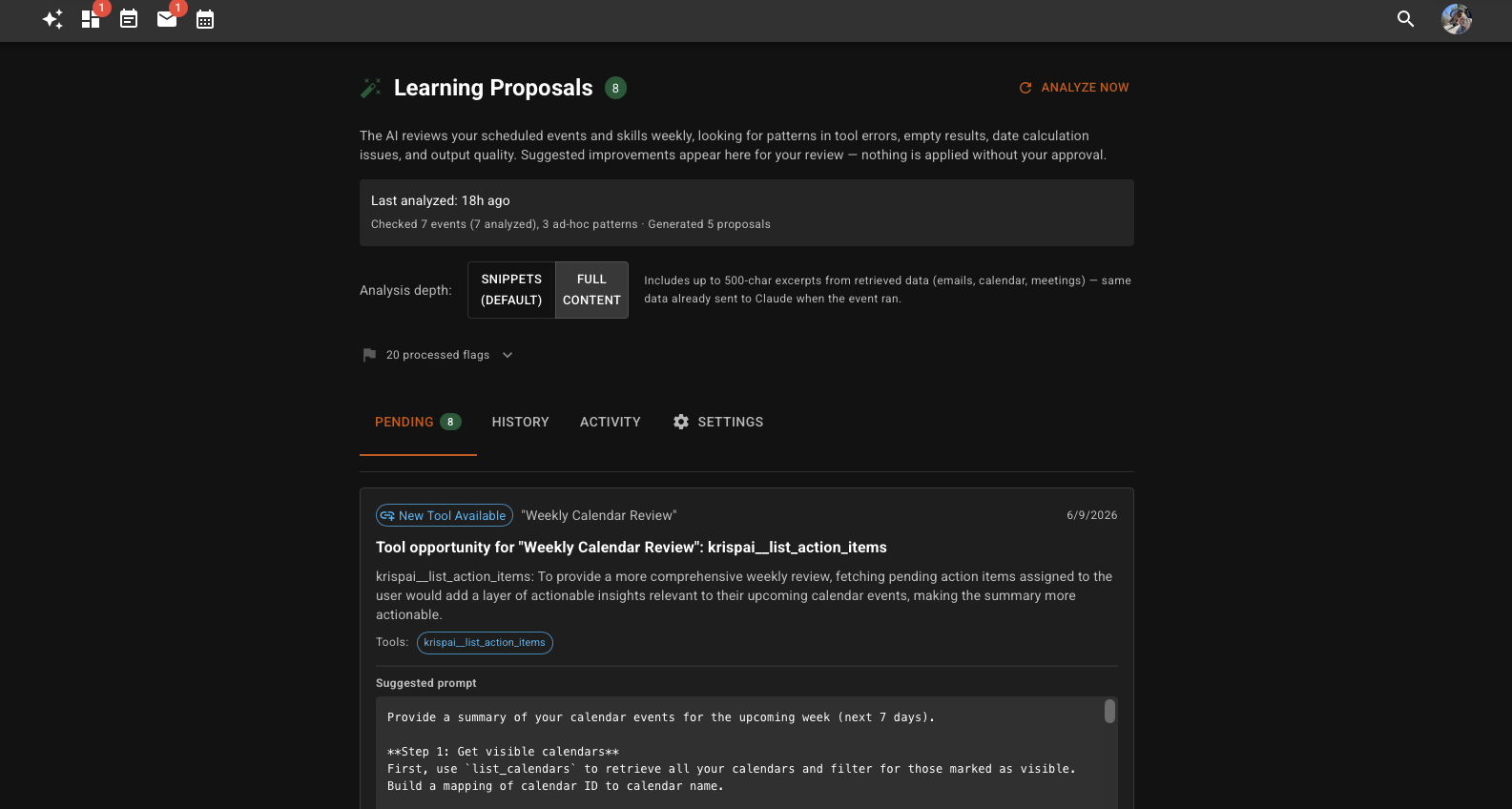
The output of all this analysis is a structured list of learning proposals.
Proposals You Can Accept, Edit, or Dismiss
Each proposal contains: what changed, why the system thinks this will help, the exact current prompt, the exact proposed replacement, and - when possible - a dry-run preview of what the new prompt would have produced against a real historical run.
That preview is important. I didn’t want you accepting changes on faith. You should be able to see the difference before you commit to it.
Proposals come in different categories. Some refine an existing automation’s prompt. Some suggest creating a new skill for something you keep doing ad-hoc. Some add guidance for how the AI calls tools, or flag that a prompt is referencing a tool that no longer exists. Some propose changes to the global instructions that apply to every conversation - triggered when the system detects recurring corrections across many interactions.
You can edit the proposed prompt before accepting. Your version wins.
If you consistently dismiss the same type of proposal, the system takes the hint and stops generating that type. It learns your limits too.
Did It Actually Help?
Here’s the accountability mechanism I’m most pleased with: after you accept a proposal, KAIPARR measures whether it actually worked.
After enough time has passed and enough new runs have accumulated on the updated prompt, the system captures a fresh quality snapshot and compares it to the baseline recorded at the moment of acceptance. Measurable improvement means the proposal is stored as a successful precedent and used to calibrate future suggestions. Measurable regression means a new proposal is automatically generated - recommending either a revert or a further refinement.
When an automation sustains a long streak of excellent quality scores, the system sends you a notification: this automation has reached a stable, excellent state. No intervention needed. I think of this as the system graduating an automation from monitored to trusted.
What If This Became the Norm?
What if every AI system worked this way? What if the standard expectation wasn’t “AI does a thing” but “AI does a thing, critiques the thing, learns from your reaction to the thing, and gets measurably better over time”?
We’re not there yet - not as an industry. Most AI systems are still remarkably passive about their own quality. They respond, they don’t reflect.
KAIPARR’s learning system isn’t magic. It’s engineering: careful logging, adversarial review, version-aware feedback, statistical analysis, and a disciplined before/after measurement framework. None of the individual pieces are mysterious. What’s unusual is putting them together into a coherent loop that runs automatically without requiring you to think about it.
The goal was never to build an AI that’s perfect on day one. The goal was to build one that’s better on day 100 than it was on day one - because of you, not despite you.
Brian Roy is the founder of KAIPARR. He’s been building software systems that learn for a long time, and remains appropriately skeptical about when they actually do.